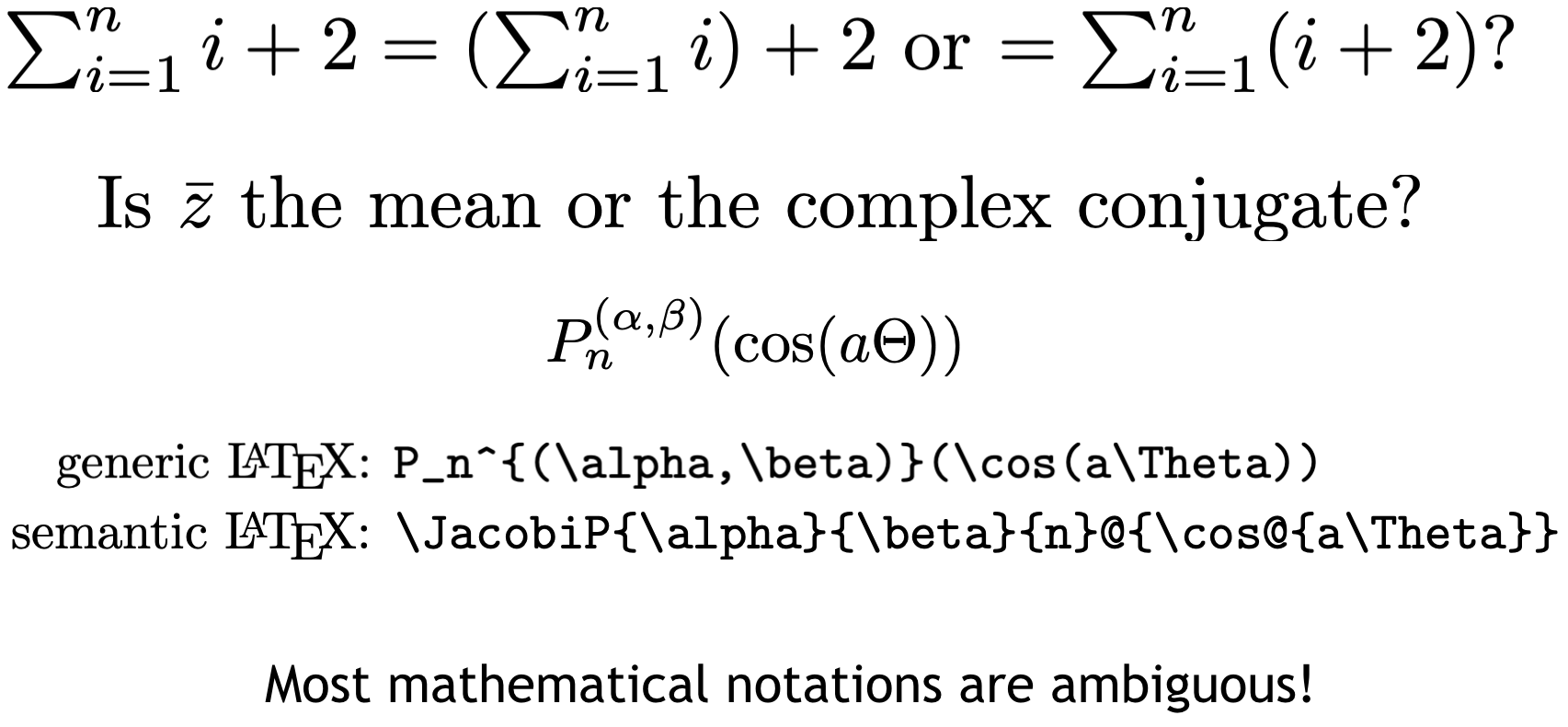|
My primary research interest is differentiable relaxations in machine learning.
In particular, I'm interested in
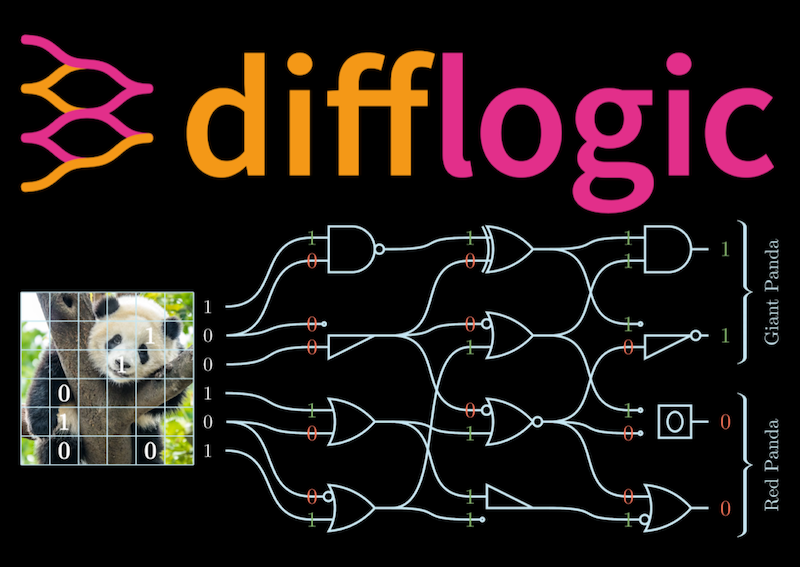
differentiable logic gate networks for extremely efficient inference,
differentiable sorting (networks) for weakly-supervised learning,
differentiable rendering,
as well as general
stochastic gradient estimation and
optimization.
Currently, I am a postdoctoral researcher at Stanford University in Stefano Ermon's group.
Previously, I have been working, i.a., at the University of Konstanz, at TAU, DESY, PSI, and CERN.
|

|
|
Research
The focus of my research lies in differentiable relaxations of non-differentiable operations in machine learning.
Differentiable relaxations enable a plethora of optimization tasks:
from optimizing logic gate networks [1, 2]
and optimizing through the 3D rendering pipeline [3, 4, 5]
to differentiating sorting and ranking [6, 7]
for supervised [8]
and self-supervised [9] learning.
Beyond differentiable algorithms, this branches out into various domains including
stochastic gradient estimation [10, 11],
analytical distribution propagation [12],
second-order optimization [10, 13],
uncertainty quantification [12],
fairness [14, 15],
and efficient neural architectures [1, 2, 16].
|
|
|
Convolutional Differentiable Logic Gate Networks
Felix Petersen,
Hilde Kuehne,
Christian Borgelt,
Julian Welzel,
Stefano Ermon
in Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS 2024) (Oral)
YouTube Code (will be updated soon) NeurIPS Oral
|
|
|
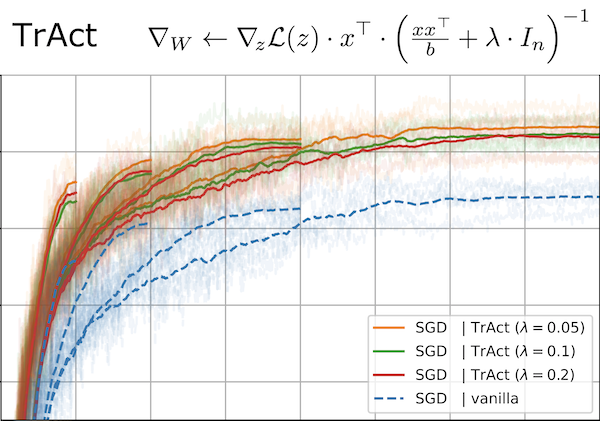
TrAct: Making First-layer Pre-Activations Trainable
Felix Petersen,
Christian Borgelt,
Stefano Ermon
in Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS 2024)
YouTube
|
|
|
Newton Losses: Using Curvature Information for Learning with Differentiable Algorithms
Felix Petersen,
Christian Borgelt,
Tobias Sutter,
Hilde Kuehne,
Oliver Deussen,
Stefano Ermon
in Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS 2024)
YouTube
|
|
|
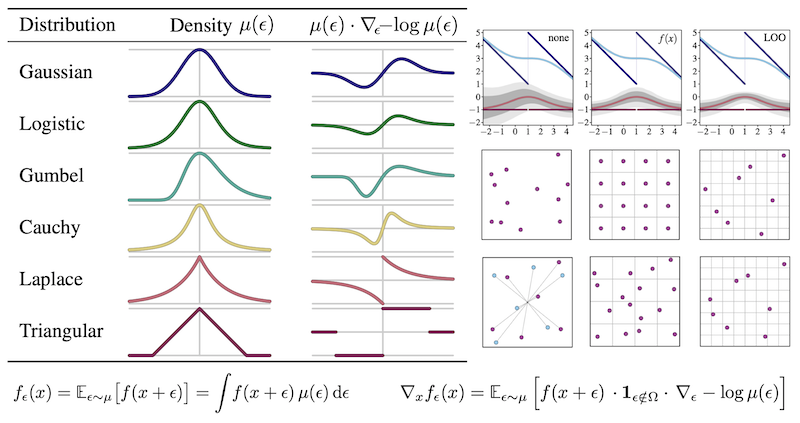
Generalizing Stochastic Smoothing for Differentiation and Gradient Estimation
Felix Petersen,
Christian Borgelt,
Aashwin Mishra,
Stefano Ermon
arXiv preprint
|
|
|
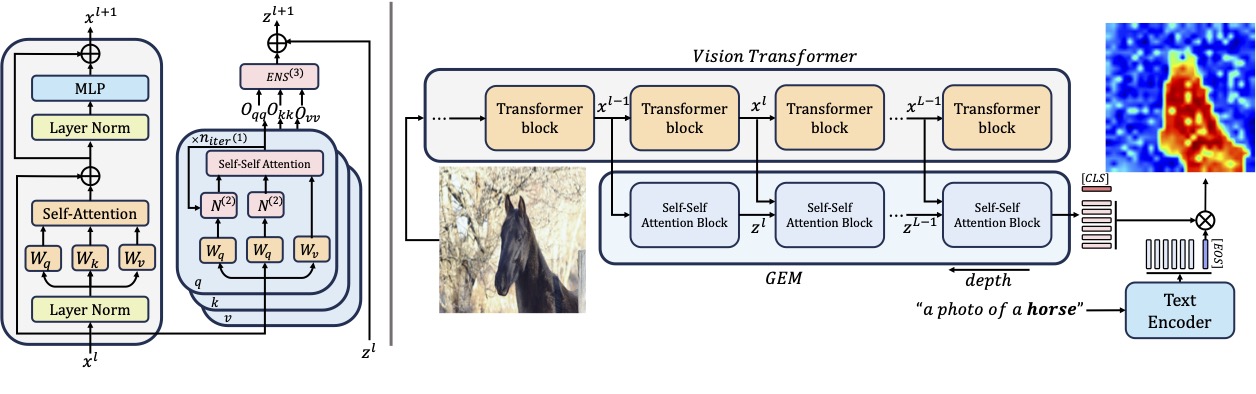
Grounding Everything: Emerging Localization Properties in Vision-Language Transformers
Walid Bousselham,
Felix Petersen,
Vittorio Ferrari,
Hilde Kuehne
in Proc. of the Conference on Computer Vision and Pattern Recognition (CVPR 2024)
Demo Code
|
|
|
Uncertainty Quantification via Stable Distribution Propagation
Felix Petersen,
Aashwin Mishra,
Hilde Kuehne,
Christian Borgelt,
Oliver Deussen,
Mikhail Yurochkin
in Proc. of the International Conference on Learning Representations (ICLR 2024)
|
|
|
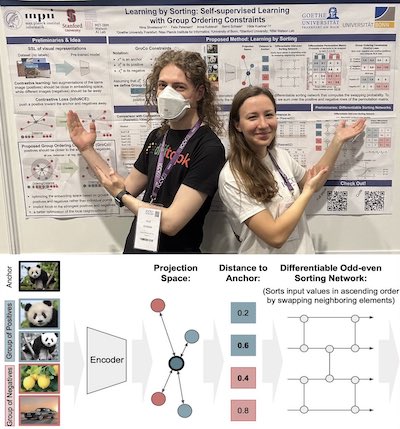
Learning by Sorting: Self-supervised Learning with Group Ordering Constraints
Nina Shvetsova,
Felix Petersen,
Anna Kukleva,
Bernt Schiele,
Hilde Kuehne
in Proc. of the International Conference on Computer Vision (ICCV 2023)
Code
|
|
|
Neural Machine Translation for Mathematical Formulae
Felix Petersen,
Moritz Schubotz,
Andre Greiner-Petter,
Bela Gipp
in Proc. of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023)
YouTube
|
|
|
ISAAC Newton: Input-based Approximate Curvature for Newton's Method
Felix Petersen,
Tobias Sutter,
Christian Borgelt,
Dongsung Huh,
Hilde Kuehne,
Yuekai Sun,
Oliver Deussen
in Proc. of the International Conference on Learning Representations (ICLR 2023)
YouTube Code
|
|
|
Deep Differentiable Logic Gate Networks
Felix Petersen,
Christian Borgelt,
Hilde Kuehne,
Oliver Deussen
in Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS 2022)
Code
|
|
|
Domain Adaptation meets Individual Fairness. And they get along.
Debarghya Mukherjee*,
Felix Petersen*,
Mikhail Yurochkin,
Yuekai Sun
in Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS 2022)
|
|
|
Learning with Differentiable Algorithms
Felix Petersen
PhD thesis (summa cum laude), University of Konstanz
|
|
|
Differentiable Top-k Classification Learning
Felix Petersen,
Hilde Kuehne,
Christian Borgelt,
Oliver Deussen
in Proceedings of the 39th International Conference on Machine Learning (ICML 2022)
YouTube Code
|
|
|
GenDR: A Generalized Differentiable Renderer
Felix Petersen,
Christian Borgelt,
Bastian Goldluecke,
Oliver Deussen
in Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR 2022)
YouTube Code
|
|
|
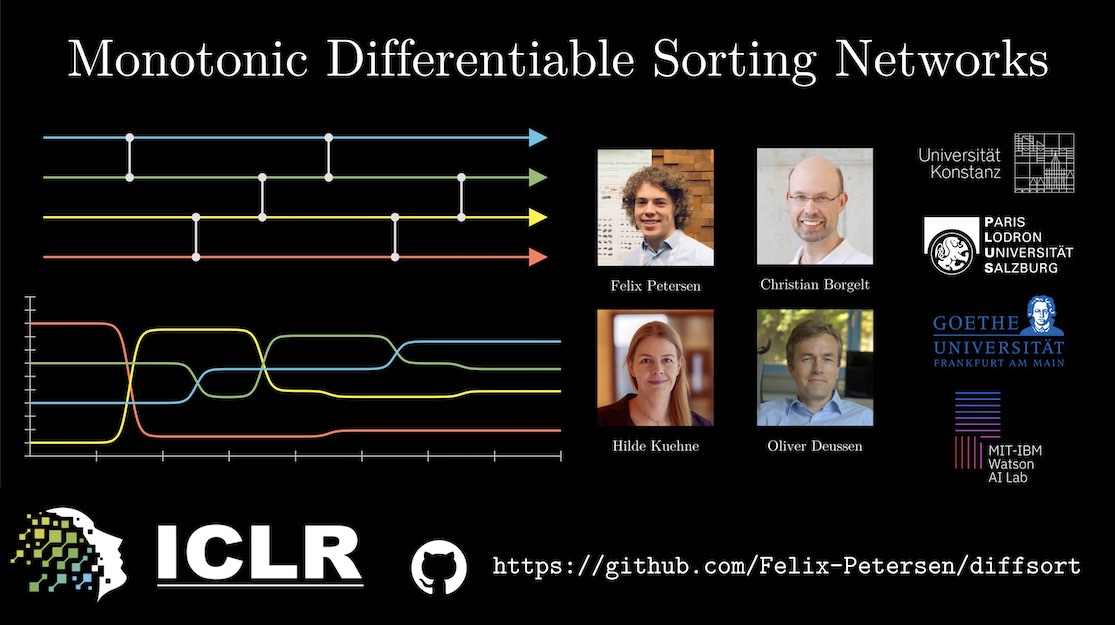
Monotonic Differentiable Sorting Networks
Felix Petersen,
Christian Borgelt,
Hilde Kuehne,
Oliver Deussen
in Proceedings of the International Conference on Learning Representations (ICLR 2022)
YouTube Code / diffsort library
|
|
|
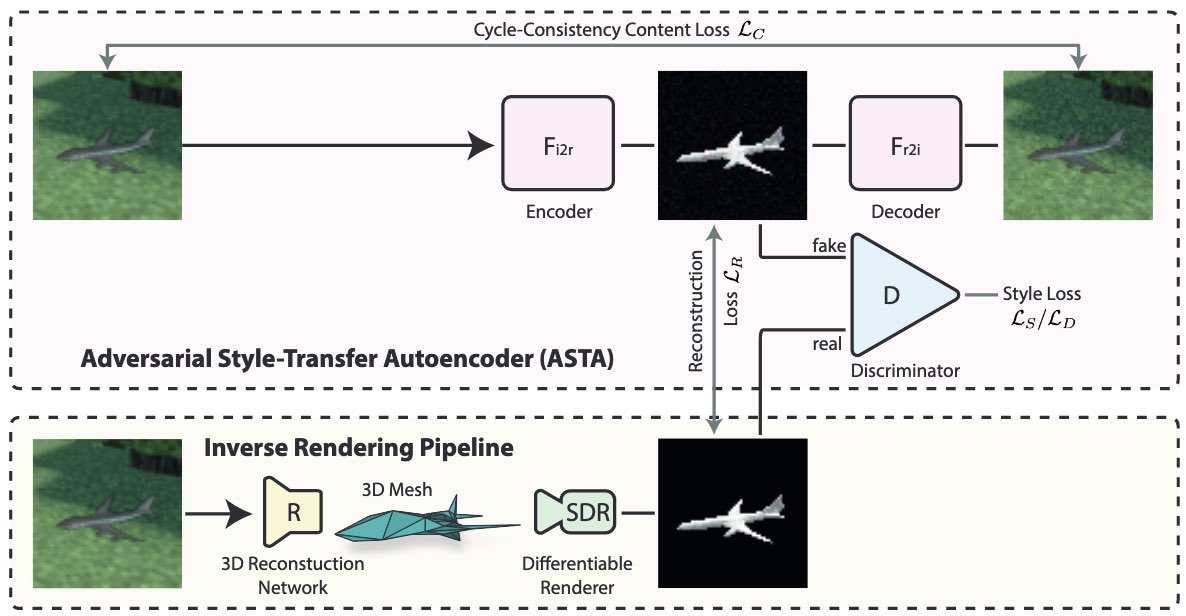
Style Agnostic 3D Reconstruction via Adversarial Style Transfer
Felix Petersen,
Hilde Kuehne,
Bastian Goldluecke,
Oliver Deussen
in Proceedings of the IEEE Winter Conf. on Applications of Computer Vision (WACV 2022)
YouTube
|
|
|
Learning with Algorithmic Supervision via Continuous Relaxations
Felix Petersen,
Christian Borgelt,
Hilde Kuehne,
Oliver Deussen
in Proceedings of the 35th International Conference on Neural Information Processing Systems (NeurIPS 2021)
YouTube Code / AlgoVision library
|
|
|
Post-processing for Individual Fairness
Felix Petersen*,
Debarghya Mukherjee*,
Yuekai Sun,
Mikhail Yurochkin
in Proceedings of the 35th International Conference on Neural Information Processing Systems (NeurIPS 2021)
YouTube Code
|
|
|
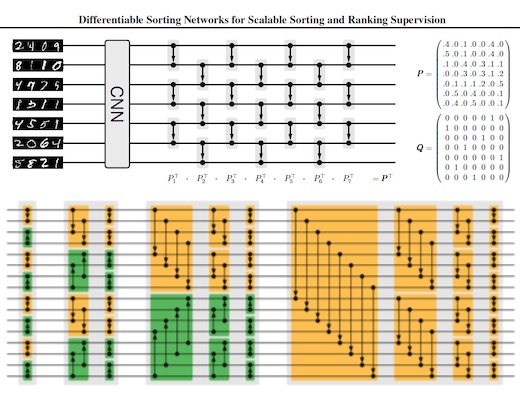
Differentiable Sorting Networks for Scalable Sorting and Ranking Supervision
Felix Petersen,
Christian Borgelt,
Hilde Kuehne,
Oliver Deussen
in Proceedings of the 38th International Conference on Machine Learning (ICML 2021)
YouTube
|
|
|
AlgoNet: C∞ Smooth Algorithmic Neural Networks
Felix Petersen,
Christian Borgelt,
Oliver Deussen
|
|
|
Pix2Vex: Image-to-Geometry Reconstruction using a Smooth Differentiable Renderer
Felix Petersen,
Amit H. Bermano,
Oliver Deussen,
Daniel Cohen-Or
|
|
|
Towards Formula Translation using Recursive Neural Networks
Felix Petersen,
Moritz Schubotz,
Bela Gipp
in Proceedings of the 11th Conference on Intelligent Computer Mathematics (CICM), 2018
|
|
|
LaTeXEqChecker
- A framework for checking mathematical semantics in LaTeX documents
Felix Petersen
Presented in the Special Session of the 11th Conference on Intelligent Computer Mathematics (CICM), 2018
Slides
|
|